 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMiT: RL-Guided Mid-Training for Iterative LLM Evolution
Feb 03, 2026Standard training pipelines for large language models (LLMs) are typically unidirectional, progressing from pre-training to post-training. However, the potential for a bidirectional process--where insights from post-training retroactively improve the pre-trained foundation--remains unexplored. We aim to establish a self-reinforcing flywheel: a cycle in which reinforcement learning (RL)-tuned model strengthens the base model, which in turn enhances subsequent post-training performance, requiring no specially trained teacher or reference model. To realize this, we analyze training dynamics and identify the mid-training (annealing) phase as a critical turning point for model capabilities. This phase typically occurs at the end of pre-training, utilizing high-quality corpora under a rapidly decaying learning rate. Building upon this insight, we introduce ReMiT (Reinforcement Learning-Guided Mid-Training). Specifically, ReMiT leverages the reasoning priors of RL-tuned models to dynamically reweight tokens during the mid-training phase, prioritizing those pivotal for reasoning. Empirically, ReMiT achieves an average improvement of 3\% on 10 pre-training benchmarks, spanning math, code, and general reasoning, and sustains these gains by over 2\% throughout the post-training pipeline. These results validate an iterative feedback loop, enabling continuous and self-reinforcing evolution of LLMs.
ARTIS: Agentic Risk-Aware Test-Time Scaling via Iterative Simulation
Feb 03, 2026Current test-time scaling (TTS) techniques enhance large language model (LLM) performance by allocating additional computation at inference time, yet they remain insufficient for agentic settings, where actions directly interact with external environments and their effects can be irreversible and costly. We propose ARTIS, Agentic Risk-Aware Test-Time Scaling via Iterative Simulation, a framework that decouples exploration from commitment by enabling test-time exploration through simulated interactions prior to real-world execution. This design allows extending inference-time computation to improve action-level reliability and robustness without incurring environmental risk. We further show that naive LLM-based simulators struggle to capture rare but high-impact failure modes, substantially limiting their effectiveness for agentic decision making. To address this limitation, we introduce a risk-aware tool simulator that emphasizes fidelity on failure-inducing actions via targeted data generation and rebalanced training. Experiments on multi-turn and multi-step agentic benchmarks demonstrate that iterative simulation substantially improves agent reliability, and that risk-aware simulation is essential for consistently realizing these gains across models and tasks.
ToolACE-MCP: Generalizing History-Aware Routing from MCP Tools to the Agent Web
Jan 13, 2026With the rise of the Agent Web and Model Context Protocol (MCP), the agent ecosystem is evolving into an open collaborative network, exponentially increasing accessible tools. However, current architectures face severe scalability and generality bottlenecks. To address this, we propose ToolACE-MCP, a pipeline for training history-aware routers to empower precise navigation in large-scale ecosystems. By leveraging a dependency-rich candidate Graph to synthesize multi-turn trajectories, we effectively train routers with dynamic context understanding to create the plug-and-play Light Routing Agent. Experiments on the real-world benchmarks MCP-Universe and MCP-Mark demonstrate superior performance. Notably, ToolACE-MCP exhibits critical properties for the future Agent Web: it not only generalizes to multi-agent collaboration with minimal adaptation but also maintains exceptional robustness against noise and scales effectively to massive candidate spaces. These findings provide a strong empirical foundation for universal orchestration in open-ended ecosystems.
Agent-Dice: Disentangling Knowledge Updates via Geometric Consensus for Agent Continual Learning
Jan 08, 2026Large Language Model (LLM)-based agents significantly extend the utility of LLMs by interacting with dynamic environments. However, enabling agents to continually learn new tasks without catastrophic forgetting remains a critical challenge, known as the stability-plasticity dilemma. In this work, we argue that this dilemma fundamentally arises from the failure to explicitly distinguish between common knowledge shared across tasks and conflicting knowledge introduced by task-specific interference. To address this, we propose Agent-Dice, a parameter fusion framework based on directional consensus evaluation. Concretely, Agent-Dice disentangles knowledge updates through a two-stage process: geometric consensus filtering to prune conflicting gradients, and curvature-based importance weighting to amplify shared semantics. We provide a rigorous theoretical analysis that establishes the validity of the proposed fusion scheme and offers insight into the origins of the stability-plasticity dilemma. Extensive experiments on GUI agents and tool-use agent domains demonstrate that Agent-Dice exhibits outstanding continual learning performance with minimal computational overhead and parameter updates. The codes are available at https://github.com/Wuzheng02/Agent-Dice.
LoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls
Nov 18, 2025



Augmenting Large Language Models (LLMs) with external tools enables them to execute complex, multi-step tasks. However, tool learning is hampered by the static synthetic data pipelines where data generation and model training are executed as two separate, non-interactive processes. This approach fails to adaptively focus on a model's specific weaknesses and allows noisy labels to persist, degrading training efficiency. We introduce LoopTool, a fully automated, model-aware data evolution framework that closes this loop by tightly integrating data synthesis and model training. LoopTool iteratively refines both the data and the model through three synergistic modules: (1) Greedy Capability Probing (GCP) diagnoses the model's mastered and failed capabilities; (2) Judgement-Guided Label Verification (JGLV) uses an open-source judge model to find and correct annotation errors, progressively purifying the dataset; and (3) Error-Driven Data Expansion (EDDE) generates new, challenging samples based on identified failures. This closed-loop process operates within a cost-effective, open-source ecosystem, eliminating dependence on expensive closed-source APIs. Experiments show that our 8B model trained with LoopTool significantly surpasses its 32B data generator and achieves new state-of-the-art results on the BFCL-v3 and ACEBench benchmarks for its scale. Our work demonstrates that closed-loop, self-refining data pipelines can dramatically enhance the tool-use capabilities of LLMs.
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
Oct 31, 2025The rapid evolution of large language models (LLMs) has intensified the demand for effective personalization techniques that can adapt model behavior to individual user preferences. Despite the non-parametric methods utilizing the in-context learning ability of LLMs, recent parametric adaptation methods, including personalized parameter-efficient fine-tuning and reward modeling emerge. However, these methods face limitations in handling dynamic user patterns and high data sparsity scenarios, due to low adaptability and data efficiency. To address these challenges, we propose a fine-grained and instance-tailored steering framework that dynamically generates sample-level interference vectors from user data and injects them into the model's forward pass for personalized adaptation. Our approach introduces two key technical innovations: a fine-grained steering component that captures nuanced signals by hooking activations from attention and MLP layers, and an input-aware aggregation module that synthesizes these signals into contextually relevant enhancements. The method demonstrates high flexibility and data efficiency, excelling in fast-changing distribution and high data sparsity scenarios. In addition, the proposed method is orthogonal to existing methods and operates as a plug-in component compatible with different personalization techniques. Extensive experiments across diverse scenarios--including short-to-long text generation, and web function calling--validate the effectiveness and compatibility of our approach. Results show that our method significantly enhances personalization performance in fast-shifting environments while maintaining robustness across varying interaction modes and context lengths. Implementation is available at https://github.com/KounianhuaDu/Fints.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025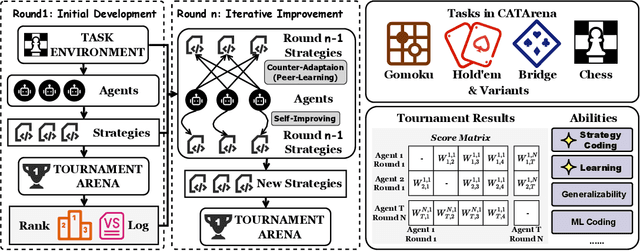
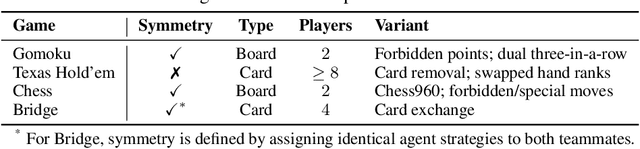
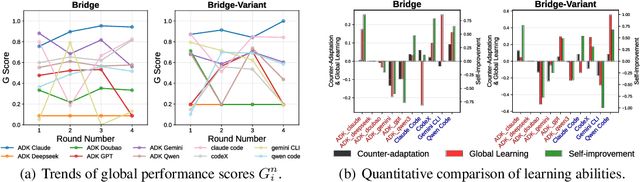
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
ColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
Sep 09, 2025With the rapid progress of multimodal large language models, operating system (OS) agents become increasingly capable of automating tasks through on-device graphical user interfaces (GUIs). However, most existing OS agents are designed for idealized settings, whereas real-world environments often present untrustworthy conditions. To mitigate risks of over-execution in such scenarios, we propose a query-driven human-agent-GUI interaction framework that enables OS agents to decide when to query humans for more reliable task completion. Built upon this framework, we introduce VeriOS-Agent, a trustworthy OS agent trained with a two-stage learning paradigm that falicitate the decoupling and utilization of meta-knowledge. Concretely, VeriOS-Agent autonomously executes actions in normal conditions while proactively querying humans in untrustworthy scenarios. Experiments show that VeriOS-Agent improves the average step-wise success rate by 20.64\% in untrustworthy scenarios over the state-of-the-art, without compromising normal performance. Analysis highlights VeriOS-Agent's rationality, generalizability, and scalability. The codes, datasets and models are available at https://github.com/Wuzheng02/VeriOS.
Fast, Slow, and Tool-augmented Thinking for LLMs: A Review
Aug 17, 2025Large Language Models (LLMs) have demonstrated remarkable progress in reasoning across diverse domains. However, effective reasoning in real-world tasks requires adapting the reasoning strategy to the demands of the problem, ranging from fast, intuitive responses to deliberate, step-by-step reasoning and tool-augmented thinking. Drawing inspiration from cognitive psychology, we propose a novel taxonomy of LLM reasoning strategies along two knowledge boundaries: a fast/slow boundary separating intuitive from deliberative processes, and an internal/external boundary distinguishing reasoning grounded in the model's parameters from reasoning augmented by external tools. We systematically survey recent work on adaptive reasoning in LLMs and categorize methods based on key decision factors. We conclude by highlighting open challenges and future directions toward more adaptive, efficient, and reliable LLMs.